除了64核心和7nm之外,AMD的Rome架构还有什么值得关注?
时间:2019-08-13 11:19:26 热度:37.1℃ 作者:网络
美国时间2019年8月7日,AMD终于发布了代号为Rome的第二代EPYC数据中心处理器。
作为数据中心领域内的首款7nm工艺x86处理器,AMD的本次发布吸引了包括HPE、Dell、联想等全球顶级系统提供商;AWS、Azure、Google Cloud等全球前三的云服务提供商以及Cray这家顶尖超算制造商登台助阵,声势空前浩大。而面对来自全球隔得的合作伙伴、客户和媒体,AMD CEO苏姿丰博士也毫不避讳的表示:AMD要把竞争带回到数据中心市场。

AMD CEO苏姿丰博士发表演讲
最高64核心、128线程、最高3.4GHz Boost频率、双路系统最高4TB内存、512MB L3缓存、全线8路DDR4 3200MHz内存支持及128 Lane PCI-E 4.0支持让AMD完全有底气说出这句话。

由AMD定义的Leadership
而从基础特性来看,本次发布的第二代EPYC处理器主要包含三大特点:7nm工艺、Zen 2核心以及Chiplet架构。
7nm无敌舰队的最后一员猛将就位
不得不说,在过去相当长的一段时间内,AMD都被工艺制程所拖累。究其原因,GF技术上的常年落后难辞其咎。不过在苏博士大刀阔斧的改革之下,AMD终于摆脱了GF的束缚,将代工工作交给了技术更先进的台积电。于是,我们便看到了Ryzen7 3000系列处理器、Radeon RX 5700系列显卡和此次发布的第二代EPYC处理器。民用处理器、图形卡、数据中心处理器,AMD的三大支柱业务终于全部享受到了7nm所带来的功耗降低及Die size减小优势。
虽然工艺与制程并不是决定一款芯片的成败,但其带来的功耗降低和面积缩减却让AMD有机会向更好能效、更多核心、更高频率发起冲击。而这些正是AMD重新站上擂台与Intel正面交锋的先决条件。
Chiplet架构——对芯片的全新理解
所谓chiplet就是将以往CPU设计中传统的单Die设计思路彻底抛弃,进而将不同功能的部分单独进行设计与制造;模块之间通过专门的互联器件和埋线技术来进行数据交换。

AMD引以为傲的Chiplet设计
目前,在Rome中,AMD采用了Core与IO分离的设计思路;在处理器最中间是集成了内存控制器、PCI-E 4.0控制器、内部互联Infinity Fabric控制器和L3缓存的IO核心,在IO核心周围则是数个Core模组(AMD将之称为CCD,每8个核心和一个Infinity Fabric为一组,64核产品只需要在IO核心周围排布8个Core模组)。这种设计思路有几个好处:
其一,不同部分单独制造可以有效缩减由良率问题所产生的成本。举个例子,在相同的技术条件下,如果同一批次的晶圆会在蚀刻过程中随机生成20个故障点,在最坏的情况下,这意味着20个die会因此报废。在采用传统的大核心设计中,如果一个晶圆只能切割出100个完整核心,那这20个故障点也就意味着良率最低会降至80%。但在chiplet思路中,AMD可以在相同尺寸的晶圆上构建更多的die(与芯片边长成平方反比),如果将die的边长缩小一半,那么一个晶圆能够切割出的die数量则至少会提升4倍,那么同样的20个坏点在最坏的情况下也只能让芯片良率降低至95%。显然,这会在极大程度上降低AMD的制造成本。
其二,由于不同功能模块彼此之间完全独立,所以进行升级或步进都会变得更容易,成本也更低。
第三,这种chiplet思路也允许AMD处理器在片上(on chip而非in chip)整合不同IP、不同公司、不同功能、不同工艺的芯片,从而快速制造出符合市场需求的全新处理器或SOC。
对于处理器来说,chiplet是一种相当先进的设计思路,能够大大降低成本,简化新产品的上市流程。不过chiplet也并非万能的,想要做好高性能的CPU产品,AMD或者台积电需要解决封装工艺上的诸多挑战,例如互联导体的电气性能、在更小的截面积上实现更高的数据带宽、如何在有效的面积上布置更多针脚等等。不过,既然Rome已经能够在这一框架下实现3.4GHz的频率和最高225W的TDP,那么AMD和台积电显然在这方面已经获得了不少成功。可以说第二代EPYC是目前chiplet模式中性能最高、功耗最高、频率最高的一种形式,个中挑战不言而喻。
Zen 2架构带来的惊喜
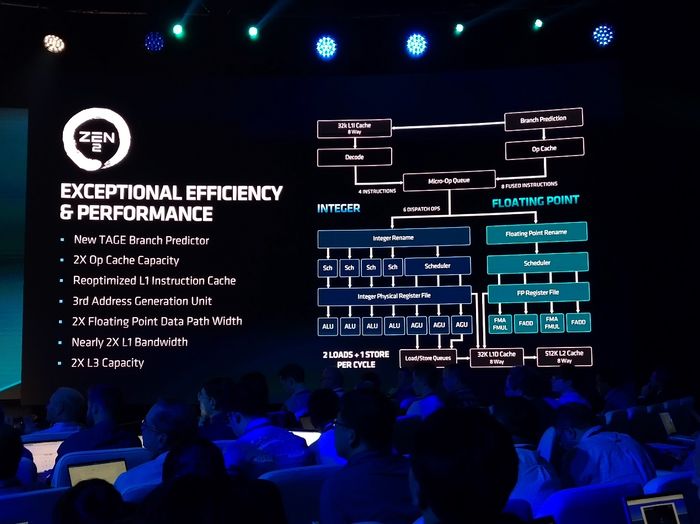
第二代EPYC的CPU设计架构
有了EPYC一代的良好开头,AMD显然已经找到了正确的架构设计方向,并在第二代EPYC中进行了更加大刀阔斧特性增强。这其中就包括名为TAGE的全新分支预测架构、2倍的OP缓存容量、经过优化的L1指令缓存、几乎倍增的L1带宽、第三代地址单元、2倍的浮点路径带宽以及2倍的L3缓存容量。
这种大刀阔斧的的性能架构增强所带来的则是23%的核心执行效率提升。而配合8路DDR4 3200内存通道和最高4TB的内存支持容量(每核心最高64GB内存),AMD在很多对内存性能敏感的应用中都可以取得性能优势。在发布会当天,苏姿丰博士表示:通过使用第二代EPYC处理器,AMD的合作伙伴和用户已经打破了全球80项性能记录。
PCI-E 4.0,威力倍增器
同时,第二代EPYC还是目前全球第一款支持PCI-E 4.0的x86处理器。2倍于PCI-E 3.0的带宽能够让高数据吞吐量的设备获得更好的性能。

支持PCI-E 4.0的赛灵斯ALVEO U50网络加速卡

博通200G以太网卡

Mellanox ConnectX-6 200G Infiniband网卡
虽然目前的多数应用形态(GPU、加速卡、网卡、HBA等)还无法充分享受到带宽翻倍所带来的性能提升,但对某些高吞吐量的FPGA(例如应用在Spark Quary上的赛灵斯ALVEO U50)来说,更高的PCI-E总线带宽显然可以极大的提升单卡性能(在现场演示中,赛灵斯Spark Quary加速卡在换装PCI-E 4.0总线后数据吞吐量可提升1.7倍)。
另外,对于下下代(就目前而言,100G网卡属于刚刚推向市场的下一代产品,那么200G自然就是下下代了)网络来说,200G网卡也是需要PCI-E 4.0来作为总线的(100G网卡换算来的总线带宽为12.8GB,刚好达到PCI-E 3.0 x16的上限,200G网卡自然就需要带宽翻倍的PCI-E 4.0了)。在演示中,博通的200G网卡在PCI-E 4.0 x16环境下的一对一双向读测试中,数据吞吐量就可以直接从192Gbps翻倍为381Gbps,性能提升立竿见影。
Mellanox的ConnectX-6 200G Infiniband网卡也有着类似的表现,一对一双向写测试从202Gbps提高至395Gbps。
当然,随着闪存技术和主控性能的进一步增强,PCI-E 4.0对于很多高性能NVMe存储设备来说同样有着长远的意义(当然,如果需要进入全面应用的话PCI-E 4.0 Switch及配套的标准也同样需要跟进和成熟)。
由于PCI-E 4.0控制器被集成在了IO核心之中,而所有产品的IO核心都完全一样,因此,无论多少核心、频率如何的第二代EPYC产品,其最大支持的PCI-E 4.0 Lane数都为128(注意,即便是在双路系统中,在安装了两颗第二代EPYC之后,这一数量也不会翻倍;AMD给出的解释是IO核心需要将一定数量的Infinity Fabric连接留给核心之间的通讯)。
但无论如何,这样的设计显然会给很多超融合、冷存储、防火墙、AI集群等应用等很多CPU负载不高的应用一个更高性价比的选择。
生态之役将成胜败关键
在性能和功能上的巨大飞跃让AMD在产品端有能力重回数据中心主流市场。但十余年的落后却让AMD在生态上还有很多课要补,而这绝非像产品发布一样一蹴而就的事。

60+合作伙伴
在发布环节,HPE、Dell、新华三、思科、超微、华硕、技嘉、华擎、泰安主板、Open 19等企业和组织就已经展示了自己的产品和设计,而在用户层面,包括AWS、Azure、Google Cloud等在内的三大云服务提供商也排除高管为AMD站台。而在国内,包括BAT在内的三大云巨头也都与AMD就第二代EPYC的应用展开了积极的合作(新华三产品已经就绪并在会议现场进行了展示)。但壮观的合作伙伴名单对于数据中心应用来说却仍然不够。

AMD EPYC的优势应用领域
除了系统制造商合作伙伴和用户之外,EPYC系列想要帮助AMD重新回到游戏还需要大量数据中心组件、操作系统、应用软件以及开源标准的支持。在AMD非公开展示的合作伙伴名录中,我们已经能够看到像三星、镁光、现代、西部数据这样的主流闪存和主控制造商,PMC这样的主控制造商,博通、Mellanox这样的网络设备制造商,微软、SUSE、红帽这样的操作系统提供商,SAP、Oracle、MongoDB、VMware、思杰这样的企业核心应用提供商以及如OpenStack、Docker、Spark、Java等开源组织的支持,但这对于整个数据中心生态来说仍旧是不够的。
那么,什么时候才算是构建了完整的企业级生态?我想应该是不需要或者无法提供合作企业名单的时候才算够吧。而AMD距离这一状态还有很长的路要走。
如果AMD能够在未来的数代产品找那个保持这种性能、核心数量、特性上的领先(或者至少持平),那么相信主动对AMD伸出橄榄枝的合作伙伴会越来越多,AMD的生态亦会越来越强大。而那时,AMD才能重新将竞争带向Intel的城门口。
不过话又说回来,更多核心、更高频率、更先进制程、Chiplet架构等的出现标志着AMD已经在向正确的方向发展。而这也让我们对EPYC系列和AMD在数据中心领域未来的发展充满了期待。

