Heliyon:基于相关特征分析和临床验证的牙周病数据驱动预测模型
时间:2024-06-28 09:05:59 热度:37.1℃ 作者:网络
牙周病(Periodontal disease, PD)已成为全球口腔保健中最重要的问题之一,其患病率为19%的成年人,全球有10亿例。PD通常会逐渐发生,从早期的牙龈出血或肿胀(牙龈炎)到更严重的牙齿和骨骼脱落(牙周炎)。由于随着年龄的增长,牙周炎是一个重要的危险因素,因此这种疾病在老年人中尤为普遍和严重,在美国,65岁及以上的老年人中有70.1%患有牙周炎。然而,如果早期诊断和治疗,这些口腔疾病大多是可以预防或延迟的。因此,早期发现和预防护理对于保护社区口腔健康至关重要。

PD可通过牙周探诊深度、临床附着水平、影像学骨质流失分析等临床方法进行诊断。世界卫生组织推荐的基于探诊深度的社区牙周指数(Community periodontal Index, CPI)是牙周严重程度的标准化分类之一。CPI可以准确诊断PD,但只能识别疾病的当前状态,没有预测能力。这一限制使得有必要寻找替代方法来预测疾病,以便及早发现和采取预防措施。
预测模型可以帮助早期发现和预后分析,因为它们可以在疾病开始或进展之前识别高危患者。这种模型可以建立在牙周危险因素(预测变量)的基础上,这些因素来自自我报告的项目,既不昂贵,也不具有侵入性,而且有利于大规模的流行病学研究。此外,该方法可以有效地评估个体处方和预防保健的患者特异性疾病风险。
为了准确的临床预测,各种评估工具、指南、算法和方法已经被开发和评估。然而,由于以下原因,PD预测模型经常遇到固有的可靠性问题。首先是可用于模型训练的数据量有限,这可能会导致随机或系统误差。预测模型基于监督学习,需要昂贵且耗时的临床测量来进行PD标记,这就是为什么大多数临床预测模型使用小患者群体(几十到几百人)。如此小的样本量限制了模型的过拟合,降低了模型的稳定性和可重复性。此外,临床患者群体的PD患病率可能与全国人群的患病率存在偏差,导致数据分布偏倚或不平衡。这些问题增加了建模偏倚的风险,降低了模型的可靠性,限制了预测模型的普遍使用。
使用大规模数据库(例如,来自数千到数万名患者的数据)进行建模可以降低偏倚风险并提高模型可靠性。此外,它还为特征选择提供了大量潜在的风险因素。这些数据库包括国家健康检查调查和电子牙科记录,并允许合理准确的预测。然而,数据驱动的PD预测不仅要准确,而且要可重复和可靠,以便在临床实践中应用。在这方面,临床验证可以是最合适的外部验证模型的性能和可重复性。数据驱动方法的程序和协议还需要涉及特征选择、临床数据收集、大型数据库建模、优化和内部外部验证。
因此,本研究旨在建立数据驱动的PD风险预测模型,并利用临床患者数据评估其性能和可靠性,进行外部验证。
方法:采用第七次韩国国民健康与营养调查(n = 10654)进行相关性分析,以确定牙周炎的显著危险因素。利用选定的因子和数据库建立牙周预测模型,然后进行5倍交叉验证和1000次bootstrap重采样的内部验证。通过自我报告问卷、临床牙周参数和x线影像分析收集临床数据(n = 120)进行外部验证。利用接收者工作特征曲线(AUC)下的面积和其他性能指标,对物流回归、支持向量机、随机森林、XGBoost和神经网络算法的预测性能进行了评估。

总体工作流程图

KNHANES和GPMC患者数据的人口学和临床特征
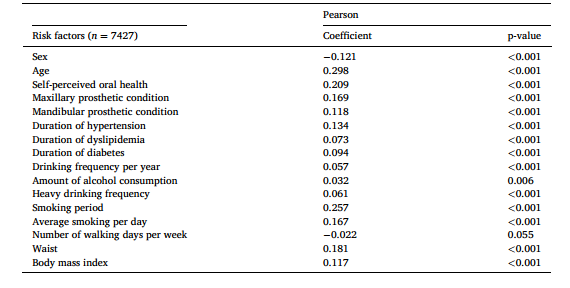
从KNHANES数据库的相关分析中提取的重要牙周危险因素

数据驱动预测模型的性能指标使用KNHANES数据库进行评估,置信区间为95%。

数据驱动预测模型的重要性。(a) RF和(b) XGB模型。

使用GPMC临床数据评估数据驱动预测模型的ROC曲线

数据驱动模型在预测其他临床因素(XGB模型)中的表现。(a) CPI3 -4, (b) CPI4, (c)探探深度(平均),(d)探探深度(个体),(e)骨质流失率(PD), (f)骨质流失率(PD+), (g)牙龈出血,(h)牙齿流失。括号内的值对应于95%的下置信区间和上置信区间

基于数据驱动模型(XGB)的年龄相关性牙周病概率预测

